
The complexity and vastness of textual data presents a continuous challenge for information retrieval, data analysis, machine learning, and artificial intelligence applications. One essential concept that stands as a cornerstone in addressing these challenges is TF-IDF (Term Frequency-Inverse Document Frequency), a numerical representation that encapsulates the importance of a word in a document relative to a collection of documents.
This article explores the various facets of TF-IDF, delving into its mechanisms, applications, and impact across a diverse range of fields. From basic text representation to sophisticated search engine functionality, from document clustering and classification to information retrieval and recommendation systems, from enhancing chatbots to feature selection in text mining, TF-IDF plays a pivotal role.
The material covered within highlights the cross-domain applicability of TF-IDF, emphasizing its significance in various sectors such as marketing, finance, healthcare, and social sciences. The exploration will not only detail the mathematical underpinnings but also provide real-world examples, illustrating how TF-IDF serves as a bridge between raw text and actionable insights.
Through a structured examination of TF-IDF, we will unveil how this concept has become an integral part of modern data analysis, a versatile tool in text processing, and an indispensable element in the growing and dynamic landscape of data-driven technologies. Whether you are a seasoned professional or new to the field, the insights provided will deepen your understanding of how TF-IDF contributes to transforming complex data into structured, meaningful knowledge.
Definition of TF-IDF
TF-IDF stands for Term Frequency-Inverse Document Frequency. It is a numerical statistic used in text mining and information retrieval to reflect how important a word is to a document within a collection or corpus. This statistic combines two components: Term Frequency (TF), which measures the occurrence of a term in a document, and Inverse Document Frequency (IDF), which diminishes the weight of terms that occur frequently across a set of documents.
TF-IDF aims to represent the significance of a particular word or term in a document, relative to a collection of documents or corpus. The TF measure assesses the importance of the term within a single document, while the IDF measure evaluates how unique or common that term is across the entire document collection. By multiplying these two components, TF-IDF gives a weight to each term in a document, with higher weights assigned to terms that appear frequently in a specific document but rarely across the entire corpus.
This approach provides a balanced view, allowing words that are unique to a particular document to be emphasized, thus highlighting the specific character or theme of that document within the broader context. The methodology of TF-IDF has been widely adopted in various applications such as search engine ranking, document clustering, and text summarization, among others.
Overall, TF-IDF is a fundamental concept in text analysis and information retrieval, allowing for a more nuanced and contextual understanding of the importance of words within a specific document and across a collection of documents. It helps in distinguishing the relevance and specificity of terms, facilitating more precise information extraction and search functionality.
Term Frequency Explanation
Term Frequency is a measure of how frequently a specific term or word appears within a given document. It can be calculated simply as the count of occurrences of a term in the document, or it may be normalized by dividing the count by the total number of words in the document. By doing this, Term Frequency provides a proportion that represents the importance of that term within the document.
This approach has practical relevance in understanding the subject matter or theme of the document. For instance, in a scientific paper about climate change, words like “temperature,” “carbon,” and “environment” might occur more frequently, thereby receiving higher TF values. These high TF values would then indicate the central focus or topic of the document.
However, it is worth noting that not all frequent terms are necessarily important. Common words like “and,” “the,” “is,” and other similar words (collectively referred to as “stopwords”) might appear frequently in nearly all documents, but they usually don’t carry significant meaning related to the specific content. In some TF calculations, stopwords may be filtered out or down-weighted to avoid skewing the analysis.
Moreover, different variations of TF can be used depending on the application. For example, binary TF counts only the presence or absence of a term, while log normalization can be applied to reduce the bias of very frequent terms.
In the context of TF-IDF, Term Frequency works in conjunction with Inverse Document Frequency to balance the local importance of a word (its frequency within a specific document) against its global importance (its frequency across all documents in the corpus). This duality allows TF-IDF to provide a more refined and contextual analysis of the significance of words within texts, contributing to its usage in a wide variety of applications such as text mining, search engines, and information retrieval.
Inverse Document Frequency Explanation
The next crucial part of the TF-IDF concept is Inverse Document Frequency (IDF). While Term Frequency focuses on the importance of a word within a single document, Inverse Document Frequency assesses how unique or rare that word is across the entire corpus or collection of documents.
IDF is calculated as the logarithm of the total number of documents in the corpus divided by the number of documents containing the term of interest. Mathematically, it is expressed as:
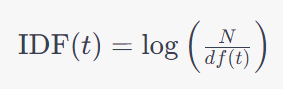
where N is the total number of documents, and df(t) is the number of documents containing the term t.
The purpose of IDF is to give higher weight to terms that are less frequent across the corpus. If a word appears in almost every document, its IDF will be close to zero, meaning it is not very distinctive and probably doesn’t carry specific meaning or relevance to particular topics within the corpus. Conversely, if a word appears in only a few documents, its IDF will be higher, indicating that it may be more significant or specialized.
This aspect of IDF serves to filter out common words that might have high Term Frequencies but are not particularly informative (e.g., “and,” “the,” “is”, collectively referred to as “stopwords”). By contrast, it emphasizes words that are unique to specific documents and are likely to be more indicative of their unique themes or subjects.
Combining IDF with TF (by multiplying the two values) yields the TF-IDF weight, a measure that reflects both the local importance of a word within a specific document and its relative rarity or distinctiveness across the entire document collection.
IDF is an essential tool in text analysis and information retrieval, helping to identify words that are not only frequent within individual documents but also distinct across a broader context. This dual focus enables more refined search and analysis functions, allowing for the extraction of more meaningful and relevant information from large and diverse text datasets.
In various applications, modifications to the basic IDF formula might be employed to suit specific needs or to provide different perspectives on term importance. Nonetheless, the fundamental idea remains the same: balancing the local significance of terms against their global prevalence to create a more nuanced and context-aware representation of text data.
Multiplying TF and IDF
The combination of both Term Frequency (TF) and Inverse Document Frequency (IDF) leads to the complete TF-IDF statistic. This combination plays a pivotal role in text analysis and information retrieval by encapsulating the local importance and the global rarity of a term.
- Calculation of TF-IDF: The TF-IDF weight for a specific term in a particular document is calculated by multiplying the TF and IDF values for that term. The mathematical representation is:
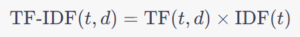
TF-IDF(t,d) = TF(t,d) X IDF(t) where t is the term, and d is the document.
- Balancing Local and Global Significance: By multiplying TF and IDF, the TF-IDF weight gives a comprehensive view of a word’s importance. The TF aspect reflects how often the term appears in a specific document, while the IDF part indicates how unique or rare that term is across the complete collection of documents. By multiplying the two together, this approach ensures that both local and global factors are taken into account.
- Emphasizing Distinctive Words: The multiplication emphasizes words that are frequent in a particular document but not common across the entire corpus. A word with a high TF but low IDF (common across all documents) will have a lower TF-IDF value, while a word with high TF and high IDF (unique to specific documents) will have a higher TF-IDF value.
- Importance in Text Representation: TF-IDF is used in text processing tasks to transform a document into a vector of numerical values. These vectors can then be analyzed using various machine learning and data mining techniques, making TF-IDF a versatile tool in representing text in a format that can be processed computationally.
- Potential Variations: Depending on specific applications and requirements, different variations and normalization techniques can be applied to the TF or IDF components. This flexibility allows TF-IDF to be tailored to various contexts and goals, enhancing its effectiveness in different scenarios.
Multiplying TF and IDF to form the TF-IDF weight is the cornerstone of text analysis and information retrieval systems. It integrates the local importance of a term (as measured by TF) with its global rarity or distinctiveness (as measured by IDF). The resulting TF-IDF weight serves as a robust and flexible measure, providing insightful perspectives on the significance of words within individual documents and across entire collections. Whether for search engine ranking, document classification, or other text processing tasks, the combination of TF and IDF into TF-IDF offers a powerful and widely used approach to understanding and representing text data.
Applications in Text Analysis
With this understanding the mathematical foundation and significance of TF-IDF here is a look at some of the real-world scenarios and applications of TD-IDF:
- Search Engines: Search engines utilize TF-IDF to rank documents in response to user queries. By calculating the TF-IDF values for the terms in a query, the engine can identify and rank documents that are most relevant to the given search terms.
- Document Classification and Clustering: TF-IDF can be used to transform documents into numerical vectors, which are then processed using machine learning algorithms for classification or clustering. This is vital in tasks like spam filtering, sentiment analysis, or grouping related documents together.
- Text Summarization: By identifying terms with high TF-IDF values, a system can recognize the most relevant and distinctive parts of a document. This information can be used to create concise and informative summaries of large texts.
- Information Retrieval: In libraries and information centers, TF-IDF can be used to develop systems that enable efficient retrieval of documents. It helps in matching user needs with relevant documents in vast collections.
- Recommender Systems: E-commerce platforms and content providers can utilize TF-IDF to analyze user behavior and preferences. By understanding the terms and topics that resonate with a user, personalized recommendations can be made.
- Semantic Analysis: In combination with other techniques, TF-IDF contributes to the understanding of the semantic content of texts. It helps in identifying themes, trends, and patterns in large text corpora.
- Feature Selection in Text Mining: TF-IDF may be employed as a feature selection method to identify the most important terms in a document. This reduces the dimensionality of the data, making subsequent analysis more computationally efficient.
- Cross-Language Information Retrieval: By applying TF-IDF on translated keywords or phrases, systems can facilitate information retrieval across different languages, supporting global accessibility and interaction.
- Legal and Forensic Analysis: Analyzing legal documents or forensically investigating communication trails can benefit from TF-IDF. It helps in pinpointing specific terms or patterns that might be indicative of legal relevance or criminal activity.
The practical applications of TF-IDF extend across a many fields and functions, highlighting its versatility and effectiveness. From enhancing user experience in online search to supporting academic research and commercial activities, TF-IDF serves as a vital tool in text processing and analysis. Its ability to quantify the relevance and uniqueness of terms within and across documents translates into a wide array of implementations, making TF-IDF a fundamental concept with broad-reaching impact.
Example Use in Chatbots
The utilization of TF-IDF in the development and functionality of chatbots highlights the adaptability of this concept:
- Understanding User Queries: Chatbots use TF-IDF to analyze user queries, helping to identify the most relevant and unique terms within the input. This aids the chatbot in interpreting the user’s intent and generating an appropriate response.
- Content Recommendation: For chatbots involved in customer service or sales, TF-IDF can assist in recommending products, services, or informational content that aligns with the user’s queries or preferences. By analyzing the TF-IDF values of terms, chatbots can match user needs with corresponding offerings.
- Personalized Interaction: By maintaining a profile of past user interactions and applying TF-IDF, chatbots can provide personalized responses that reflect an understanding of the user’s interests, questions, and previous engagements.
- Conversation Flow Optimization: TF-IDF helps chatbots in managing conversation flow by identifying key terms and guiding the dialogue in a direction that is contextually relevant. It assists in maintaining coherence and logical progression within the conversation.
- Multilingual Support: Chatbots supporting multiple languages can apply TF-IDF to translated terms, ensuring that the importance of words is maintained across different linguistic contexts. This promotes consistent and accurate responses in various languages.
- Integration with Knowledge Bases: Chatbots often rely on extensive knowledge bases to provide detailed answers. TF-IDF can be used to search and retrieve the most relevant information from these databases in response to user queries, enhancing the chatbot’s effectiveness in providing accurate information.
- Enhancing User Engagement: By recognizing the importance of specific terms through TF-IDF, chatbots can engage users with content and responses that resonate with their interests and queries. This leads to more engaging and satisfying user experiences.
- Spam and Abuse Detection: In community-driven chatbots or platforms, TF-IDF can aid in detecting spam or inappropriate content by identifying patterns or terms that are indicative of such activities.
- Analyzing Chatbot Performance: Analyzing the TF-IDF values of terms within user interactions can provide insights into the chatbot’s performance, highlighting areas for improvement or adaptation.
The application of TF-IDF in chatbots illustrates the concept’s ability to support intelligent, responsive, and personalized communication. By effectively recognizing and weighting terms within user inputs, chatbots can provide dynamic and context-aware responses, enhancing the overall user experience. The utilization of TF-IDF in chatbots reflects a broader trend of employing sophisticated text analysis techniques in the rapidly evolving field of conversational AI. Whether in customer service, entertainment, education, or other domains, TF-IDF serves as a valuable tool in the design and operation of chatbots, contributing to their ability to engage and assist users in diverse and meaningful ways.
Importance in Information Retrieval
The role of TF-IDF in feature selection within text mining, a critical aspect of many applications, including machine learning and data analytics:
- Dimensionality Reduction: In large datasets, the number of features (e.g., words in a text corpus) can be overwhelming. TF-IDF is used to identify the most significant terms, reducing the dimensionality of the dataset without losing essential information. This makes further analysis more manageable and computationally efficient.
- Improving Model Performance: By selecting features based on their TF-IDF values, models can be trained on relevant and informative attributes. This often leads to improved accuracy and predictive performance in tasks such as classification, clustering, or regression.
- Interpretability: Utilizing TF-IDF for feature selection ensures that the chosen features have clear relevance and significance within the context of the data. This enhances the interpretability of models, making it easier to understand how predictions or decisions are being made.
- Noise Reduction: TF-IDF helps in filtering out terms that are either too common or too rare to be meaningful. By focusing on terms with significant TF-IDF values, irrelevant or noisy features can be excluded, enhancing the quality of the analysis.
- Customization for Specific Applications: Depending on the goal of the analysis, TF-IDF can be tailored to focus on particular aspects of the text. For example, in sentiment analysis, it may be tuned to emphasize terms that are strongly indicative of emotional content.
- Integration with Other Techniques: TF-IDF for feature selection can be integrated with other methods and algorithms. For example, it might be combined with mutual information, chi-squared tests, or other statistical measures to create a robust feature selection strategy.
- Cross-Domain Applicability: The principles of TF-IDF-based feature selection can be applied across various domains, from marketing and finance to healthcare and social sciences. This adaptability reflects the universal relevance of identifying significant patterns within text data.
- Real-time Analysis: In applications that require real-time processing and decision-making, TF-IDF can be leveraged to quickly identify critical features, enabling timely responses.
- Enhancing Visualization: By reducing the complexity of data to essential features using TF-IDF, visualization tools can provide more lucid and insightful representations of the underlying patterns and relationships.
- Scalability: As datasets grow, TF-IDF’s ability to succinctly capture the essence of the data ensures that feature selection remains scalable. It accommodates the processing of large volumes of text without significant degradation in performance or accuracy.
The application of TF-IDF in feature selection represents a critical intersection between text analysis and data mining. By pinpointing the terms and patterns that are most representative and informative, TF-IDF serves as a vital tool in transforming raw text into structured insights. Whether in enhancing the performance of machine learning models, enabling insightful visualizations, or supporting real-time decision-making, TF-IDF’s role in feature selection underscores its significance in translating complex data into actionable knowledge. Its versatility and adaptability contribute to its wide-ranging applicability, making TF-IDF a foundational concept in modern data analytics and text mining.
Conclusion
In conclusion, the wide-ranging applications of TF-IDF illuminate its integral role in modern data analysis and text processing. From search engines to chatbots, from machine learning to real-time decision-making, TF-IDF serves as a critical bridge between raw text and actionable insights. Its ability to recognize and weight terms with precision equips it to tackle complex challenges across diverse contexts, underlining its importance as a versatile and essential tool in the ever-evolving landscape of data-driven technologies. Whether employed to enhance user experience, drive intelligent automation, or uncover hidden patterns within vast datasets, TF-IDF’s multifaceted contributions resonate across industries and disciplines, reflecting its enduring relevance and impact.
About the Author

Stephen Howell is a multifaceted expert with a wealth of experience in technology, business management, and development. He is the innovative mind behind the cutting-edge AI powered Kognetiks Chatbot for WordPress plugin. Utilizing the robust capabilities of OpenAI’s API, this conversational chatbot can dramatically enhance your website’s user engagement. Visit Kognetiks Chatbot for WordPress to explore how to elevate your visitors’ experience, and stay connected with his latest advancements and offerings in the WordPress community.
Leave a Reply
You must be logged in to post a comment.